Трансформерлерді NVIDIA NeMo AutoModel көмегімен тез әрі тиімді баптау
Жасанды интеллект саласындағы трансформерлік үлгілер – табиғи тіл өңдеу, көрініс тану және басқа да күрделі міндеттерді шешудің негізі саналады. Бұған қоса үлгілердің тиімді әрі жылдам бапталуы (fine-tuning) олардың қолдану аясының кеңеюінде маңызды рөл атқарады. NVIDIA NeMo AutoModel кітапханасы – осы процесті жеделдетуге және тиімдірек етуге арналған инновациялық шешім. Бұл мақалада трансформерлерді Nvidia NeMo AutoModel арқылы баптаудың артықшылықтары мен оның техникалық ерекшеліктері қарастырылады.
Кіріспе
Трансформер үлгілерінің дамуы жасанды интеллекттің дамуына зор серпін берді. Бұл технология қазіргі үлгілердің жоғары сапалы нәтижелеріне қойылған талаптарды қанағаттандыру үшін үнемі жетілдірілуі тиіс. Әсіресе Mixture-of-Experts (MoE) архитектурасы күрделі үлгілердің тиімділігін арттыруда жетекші орынға шықты. NVIDIA NeMo AutoModel – құны жоғары әрі үлкен көлемді MoE үлгілерін тез баптаудың бірегей құралдарының бірі.
Негізгі түсіндірме
HuggingFace Transformers айналасындағы ашық бастапқы кодтық экожүйенің негізі ретінде есептеледі. Transformers v5 жаңартуымен MoE үлгілерінің жүктемесін басқару мен динамикалық салмақ жүктеу сияқты шешімдер енгізілді. Дегенмен, үлкен көлемді үлгілерді тиімді баптау үшін қосымша оптимизациялар қажет болды.
NVIDIA NeMo AutoModel бұл мәселелерге ерекше назар аударады. Ол Transformers v5 негізінде құрылған, бірақ Expert Parallelism (эксперттерді параллель өңдеу), DeepEP (байланыс пен есептеулерді тиімді үйлестіру), TransformerEngine ядролары сияқты қосымша функцияларды қамтиды. Бұл технологиялар бірнеше GPU арасында есептеулер мен деректерді тиімді бөлуге мүмкіндік береді, нәтижесінде баптау жылдамдығы 3,4-3,7 есе өсіп, GPU жадын 29-32% үнемдеу қамтамасыз етіледі.
Контекст және мысалдар
MoE үлгілері токендерді жүздеген эксперттер арасында бағыттауда күрделілік туғызады. Бірнеше GPU арасында деректер мен есептеулерді үйлестіру арнайы инфрақұрылымды талап етеді. Transformers v5 бастапқы негізін құрса, NeMo AutoModel инженерлік шешімдерін сол негізде кеңейтеді.
Мысалы, Nemotron 3 Ultra 550B моделі толық баптау кезінде 16 NVIDIA H100 GPU кластерінде 58 ГиБ жадыны пайдаланып, 815 TPS/GPU өнімділікті көрсетті. Трансформерлердің алдыңғы нұсқалары мұндай көлемді өңдей алмады, себебі жады жетпей қалды.
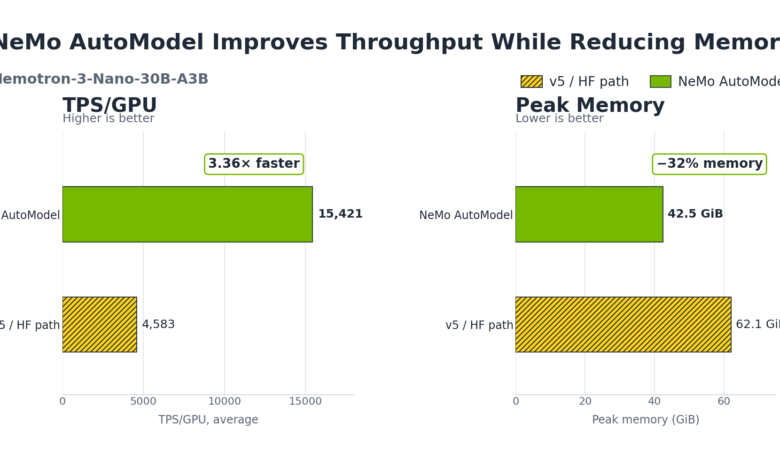
Сондай-ақ, NeMo AutoModel 30 миллиард параметрлі Nemotron 3 Nano 30B A3B және Qwen3-30B-A3B үлгілерін бір ғана сервердегі 8 GPU арқылы баптауда өнімділікті 3-4 есеге арттырды. Мысалы, Nemotron 3 Nano 30B A3B үлгісінің жад тұтынуы 62 ГиБ-дан 42,5 ГиБ-ға қысқарды, ал өңдеу уақыты бірнеше есе төмендеді.
Практикалық маңызы
NeMo AutoModel-дың ең үлкен пайдасы — ашық бастапқы кодтық экожүйеде API үйлесімділігі сақталған. Бұл әзірлеушілердің кодты мүлде өзгертпей, бар HuggingFace Transformers бағдарламаларымен жұмыс істеуіне мүмкіндік береді. Бір ғана кітапхананы ауыстыру арқылы жоғары өнімділік пен масштабталуды алуға болады.
Сонымен қатар, DeepEP және Expert Parallelism арқасында үлкен және күрделі MoE үлгілерін көп GPU-ларда тиімді әрі тұрақты түрде баптау жүзеге асады. Бұл ізденушілерге, зерттеушілерге және өндірістік қолданушыларға жылдам нәтиже алу үшін қажетті қолжетімді құрал ұсынады.
Қорытынды
NVIDIA NeMo AutoModel трансформерлік үлгілерді тез әрі тиімді баптауға бағытталған маңызды технологиялық қадам. Оның көмегімен үлкен көлемді MoE үлгілерін масштабты GPU кластерлерінде тұрақты жұмыс істетіп, баптау процесін тездетуге болады. API үйлесімділігі және бірегей оптимизациялар арқылы бұл құрал жасанды интеллект саласындағы зерттеулер мен өндірісті жаңа деңгейге апарады.
TAGS: трансформерлер, MoE үлгілері, NVIDIA NeMo, жасанды интеллект, GPU, модель баптау, HuggingFace
Дереккөз: Hugging Face Blog



