ITBench-AA: Аға деңгейдегі модельдердің агенттік кәсіптік IT міндеттеріндегі алғашқы бенчмарктегі нәтижелері
Кіріспе
Жасанды интеллект саласында модельдердің кәсіптік IT тапсырмаларын шешудегі деңгейін анықтайтын бенчмарктер маңызды рөл атқарады. ITBench-AA — IBM және Artificial Analysis компаниялары бірлесіп әзірлеген, агенттік кәсіптік IT міндеттерін бағалауға арналаған алғашқы кешенді бенчмарк. Бұл жобаның ерекше мәні – ол кәсіпорындардың Site Reliability Engineering (SRE) бағытындағы нақты жүйелік ақауларды талдауға арналған тесттер жиынтығын ұсынады. Осы арқылы IT саласындағы жасанды интеллект модельдерінің шынайы жұмыс ортасындағы қабілеті сараланады.
Негізгі түсіндірме
ITBench-AA SRE тапсырмалары Kubernetes жүйесіндегі оқиғалар мен ақауларды анықтауға бағытталған. Модельдерге нақты уақыттағы журналдар, трассалар, оқиғалар мен метрикаларды талдау ұсынылады, олардың мақсаты – жүйелі ақаудың түпкі себептерін білу. Бұл – кешенді, көп деңгейлі инфрақұрылымды қамтитын міндеттер, мұнда дұрыс шешім табу үшін әртүрлі компоненттердің өзара байланысы мен тәуелділігін терең түсіну қажет.
Жинақ IBM компаниясының кәсіпорын деңгейіндегі IT операциялар тәжірибесіне сүйеніп, соңғы алты айда Artificial Analysis зерттеушілерімен тығыз ынтымақтасу нәтижесінде әзірленді. ITBench-AA платформасы уақыт өте SRE бағытынан бөлек, қаржылық операциялар (FinOps) және ақпараттық қауіпсіздік (CISO) салаларындағы тапсырмаларға да кеңейеді.
Контекст және мысалдар
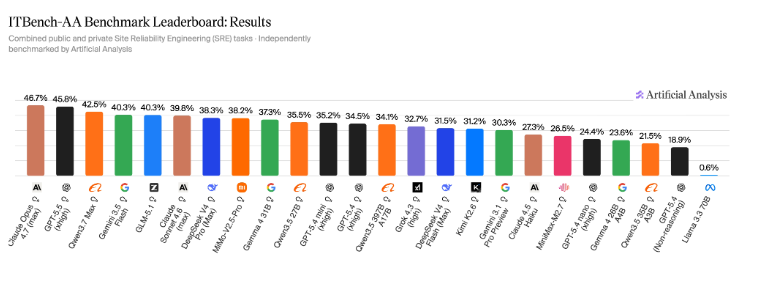
ITBench-AA SRE бенчмаркі 59 тапсырмадан тұрады, оның 40-ы жалпыға ашық, 19-ы жаңа және жабық тапсырмалар. Әрбір міндет Kubernetes оқиғасына қатысты кең ауқымды мәліметтер жинағын ұсынады. Модельдерге мысал ретінде бір тапсырмада пайдаланушыға көрінетін өнімнің ақаулықтары қарастырылады. Модель журналдар мен трассаларды зерттеп, ақау фронтенд трафигінде екенін анықтайды. Топология талдауы арқылы бұл қызметтің қай бөлігінде ақау бары нақтылайды, ал жүйедегі желілік ережелердің бірі трафикті бөгеп отырғаны анықталады. Нәтижесінде түпкі себебі – желілік саясаттың дұрыс жұмыс істемеуі болатын.
Айта кететін жайт, зерттеуде көп қадам жасау әрқашанда тиімді шешімге алып келмейтіндігі байқалады. Мысалы, Gemini 3.1 Pro Preview моделі орта есеппен 83 қадам жасаса да 30% нәтиже көрсеткен, ал Gemma 4 31B моделі 58 қадамда 37% ұпай жинаған. Бұл – ұзақ және жан-жақты іздестіру кейде қосымша анықталған, бірақ түпкі себеп болып табылмайтын механизмдер мен симптомдарды қате түрде анықтауға орын береді дегенді білдіреді.
Практикалық маңызы
ITBench-AA зерттеуі кәсіптік IT саласындағы модельдердің нақтылығын, тиімділігін және құнын салыстыратын маңызды өлшемдер жүйесін ұсынып отыр. Мысалы, ашық кодты GLM-5.1 (Reasoning) 40% тапсырма шешімінің дәлдігімен және $1.23 құнымен сапа мен шығынның жақсы балансын көрсеткен. Оның үстіне, Claude Opus 4.7 моделі 47% дәлдікпен көшбасшы болғанымен, оның жұмыс құны $5.38-ға тең – бұл кейбір компанияларға қымбат болуы мүмкін. Осылайша, ITBench-AA кәсіпорындарға өз қажеттеріне сәйкес тиімді модель таңдауға мүмкіндік береді.
ITBench-AA-ның әдістемесі мен құралдары ашық қолжетімді және Stirrup атты ортақ платформада іске асырылады. Бұл орта түрлі модельдерді әділетті түрде салыстыруға жол ашады, өйткені барлық модельдерге бірдей шарттар ұсынылады. Шешімнің сапасы қарап шыққан түпкі себептерді толық және дәл анықтауға негізделеді – бұл кәсіптік IT жүйелердің сенімділігі мен тұрақтылығын арттыру үшін маңызды.
Қорытынды
ITBench-AA агенттік кәсіптік IT тапсырмаларын бағалау саласында маңызды қадам болып табылады. Ол кәсіпорындар мен зерттеушілерге модельдердің нақты IT операцияларын талдаудағы қабілетін өлшеуге мүмкіндік берген. Қазіргі аға деңгейдегі модельдердің 50%-дан төмен нәтиже көрсетуі жасанды интеллекттің осы салада жетілдірілуге мұқтаж екенін көрсетеді. Бұл бағыттағы жұмыс модельдердің сапасын арттырып, IT инфрақұрылымын басқаруда қолданыс ауқымын кеңейтеді деп күтілуде.
Дереккөз: Hugging Face Blog



