Is it agentic enough? Open модельдерді өз құралдарында бағалау
Кіріспе
Жасанды интеллект пен агенттік бағдарламалық қамтамасыз ету салаларында модельдердің тиімділігі мен икемділігін бағалау маңызды мәселе. Атап айтқанда, ашық бастапқы коды бар үлгілердің агенттік қолдануға қаншалықты қолайлы екенін анықтау қажет. Бұл тұрғыда тек модельдің соңғы нәтиже беруіне ғана емес, оны алу процесінің қаншалықты оңтайлы әрі тиімді екендігіне мән беріледі. Жобаның негізгі мақсаты – агенттік құралдармен жұмыс істеуде модификацияланған кітапханалардың тиімділігін ашық түрде тексеріп, нақты деректер негізінде бағалау жүргізу.
Негізгі түсіндірме
Агенттік бағдарламалар тапсырманы сипаттап, қажетті кітапхананы таңдап, шақыруларды жазып, орындап, өз қателіктерін түзете алатын жүйе ретінде қарастырылады. Сондықтан кодтың дұрыстығы мен жылдамдығы маңызды болғанымен, агенттің оны тиімді басқарып, талаптарына сай қолдана алу мүмкіндігі де үлкен рөл атқарады. Мысалға, егер API күрделі немесе құжаттама ескі болса, агент қажетті ақпаратты табу үшін көп уақыт жұмсайды, нәтижесінде орындалу процесі ұзаруы және шығындар жоғарылауы ықтимал. Көптеген бенчмарк әдістері тек соңғы дұрыс нәтиже шыққанын ғана тексереді, алайда осы зерттеуде тапсырманың орындалу жолы, жұмыстың күрделілігі, сондай-ақ модель, кітапхана жаңартулары және әртүрлі тапсырмаларға қарай көрсеткіштердің өзгерісі назарда болды.
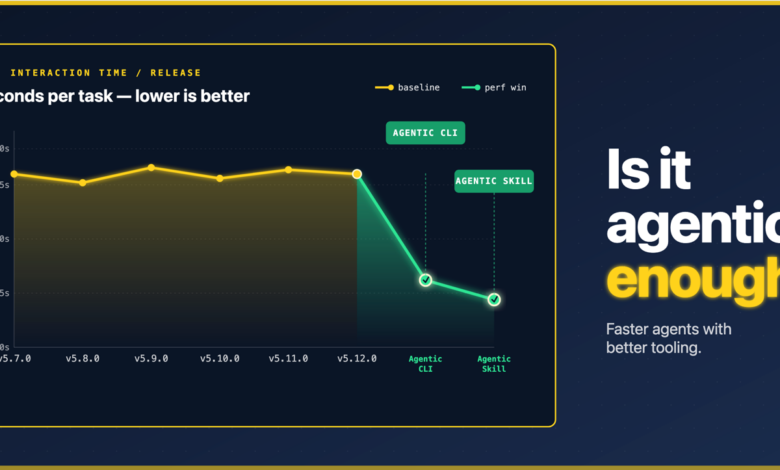
Зерттеу аясында transformers кітапханасы басты кейіпкер ретінде алынды. Бұл кітапханадағы әртүрлі модель мен нұсқаларды пайдалануда агенттің тапсырманы орындау үшін қаншалықты күш жұмсайтынын анықтау мақсат етілді. Осы тақырыпқа арналған арнайы бенчмарк құралымен, pi coding агентін қолданып, барлық өлшемдер мен параметрлер бойынша зерттеу жүргізілді.
Контекст және мысалдар
Мысал ретінде sentiment-classification (сезімталдықты классификациялау) тапсырмасы қаралды. Екі агент те дұрыс нәтиже берсе де, тапсырманы орындау жолдары айтарлықтай ерекшеленді. Бір агент Python-да 40 жолдық скрипт жазып, модель мен токенайзерді импорттап, қателер мен түзетулерді қайта-қайта тексерді. Ал екінші агент transformers кітапханасының командалық жол интерфейсін пайдаланып, бір-ақ бұйрықпен нәтижеге қол жеткізді. Нәтижесінде екі әдіс те оң жауап берсе де, бірінші агент тапсырманы орындауға әлдеқайда көп ресурс жұмсады.
Тапсырманың мәтіні: «I absolutely loved the movie, it was fantastic!» – екі агенттің әрекеті контрастты:
- Бірінші агент: Python скрипт жазып, модельдің нәтижесін өңдеді.
- Екінші агент: transformers classify —model distilbert/distilbert-base-uncased-finetuned-sst-2-english —text «I absolutely loved the movie, it was fantastic!» командасын бір рет орындады.
Бұл айырмашылық тек орындау уақытында емес, токендер саны, оқылу жеңілдігі мен қателіктер саны сияқты бағалаушыларда айқын көрінеді. Тек соңғы нәтиже ғана қарастырылатын болса, осындай маңызды факторлар ескерусіз қалады.
Практикалық маңызы
Бұл зерттеу бағдарламалық өнімдерді агенттік жұмысына ыңғайлы етіп дамытуға бағытталған нұсқаулық қызметін атқарады. Әртүрлі модельдер мен бағдарламалық кодтардағы өзгерістердің сапасын барлық қырынан бағалау арқылы құралдардың жетілдірілуін қамтамасыз етеді. Нақтырақ айтқанда:
- Модельдің сәйкестігі (match %), яғни нәтиженің тапсырмаға қаншалықты сәйкес екенін анықтау.
- Орындау уақыты мен қолданылған токен саны, олардың кешірілген, жаңадан жасалған және кэште сақталған бөліктері бойынша талдау.
- Орындау барысында пайда болған қатенің пайызы және толықтай сәтсіз аяқталған жағдайлардың бар-жоғы.
- Құралдарда енгізілген мінездемелік белгілердің (markers) қабылдануы және агенттің оларға әрекеті.
Барлық осы өлшемдер толықтай есептеліп, жан-жақты есеп беруге негіз болады. Сонымен қатар агенттің әр қадамы тіркеліп, оның нақты қандай команда орындағаны ашықтықты қамтамасыз етеді. Бұл факт негізінен жасанды интеллект жүйелерін әзірлеушілерге және зерттеушілерге төмендегідей көмектеседі:
- Агенттік түрдегі қолдануға арналған технологияларды тестілеу және бағалау.
- Құралдардың тиімділігін арттыру мақсатында міндетті өзгерістерді анықтау.
- Әртүрлі модельдер мен агенттердің нақты тапсырмаларда қалай жұмыс істейтінін салыстыру.
Қорытынды
Агенттік жұмыс істеу үшін арналған модельдер мен құралдардың тиімділігін бағалау толық нәтиже ғана емес, сонымен бірге олардың нәтижеге қалай жеткенін де саралауды талап етеді. Бұл тәсіл агенттерге бағытталған құралдар мен API-дің түсінікті, жылдам, және сенімді болуын қамтамасыз етеді. Әукетін кезеңде тек соңғы нәтиже қана емес, бүкіл орындау логикасына назар аударып, талдау жасау инновациялық даму үшін қажет. Мұндай тәсіл ашық бастапқы кодты модельдер мен құралдар экожүйесін оңтайлы жетілдіруге мүмкіндік береді және қолданушылар мен зерттеушілерге тиімділік пен икемділік ұсынады.
Дереккөз: Hugging Face Blog



